使用git更新管理雾凇词库
# 在用户文件夹目录下 %APPDATA%\Rime
# 第一次克隆,记得备份sync目录(词频优先级)与添加在cn_dicts目录下的自己的词库
git clone https://github.com/iDvel/rime-ice.git Rime --depth 1
# 之后更新就行
# 忽略本地差异更新
git stash
git pull
git stash pop
# pwsh里一条命令
git stash && git pull && git stash pop
# 右键输入法,点重新部署基础知识
Windows端
Rime输入法核心的三大模块:前端程序、输入方案和扩展增强功能。下面这个表格清晰地展示了它们各自的作用:
🧩 深入了解各个模块
🖥️ 前端程序 (以小狼毫为例):这是你在Windows系统上使用Rime的操作界面。它负责显示候选词框、处理你的按键消息,并确保输入法能在不同软件中正常工作。除了小狼毫,不同平台还有不同的前端,比如macOS上的鼠须管(Squirrel)和Android上的同文输入法(Trime)。
🧠 输入方案 (以雾凇拼音为例):输入方案是Rime的核心规则集。你选择的"雾凇拼音"(rime-ice)就是一个功能丰富的拼音输入方案。它主要包含:
词库文件(
.dict.yaml):存储了大量的词汇和对应的拼音。雾凇拼音集成了经过精心整理的现代词库,覆盖了更多新词和常用词。方案文件(
.schema.yaml):定义了输入法的各种行为,比如是否支持模糊音、如何切换中英文、使用哪些按键翻页等。
🚀 扩展增强功能 (以语言模型为例):这是让你组合体验产生质变的部分。RIME-LMDG这类语言模型的作用是大幅提升整句输入的准确性。它通过分析海量文本数据,学习到词语之间的搭配概率。当你输入一串拼音时,语言模型会介入计算,让"渐渐地就不在意了"这样的句子能一次打对,而不是错误地拆分成"不再一乐"。这有效解决了单纯依赖词库时可能出现的组词混乱问题。
Android端
下面这张表格汇总了各个核心组件的作用:
📲 安装必要的组件
安装小企鹅输入法与 Rime 插件:
从 GitHub 或 F-Droid 获取最新的小企鹅输入法 (Fcitx5 Android) 和 Rime 插件 (plugin.rime) 安装包。你可以访问 Fcitx5 Android 的 GitHub 仓库的 Release 页面下载这些安装包。
先安装小企鹅输入法,然后再安装 Rime 插件。安装完成后,在系统设置中启用小企鹅输入法。
获取薄荷拼音配置:
访问 oh-my-rime (薄荷拼音) 的 GitHub 仓库,下载其配置文件(通常可以通过
git clone或直接下载 ZIP 压缩包的方式获取)。
🔧 部署薄荷拼音配置
定位小企鹅的 Rime 数据目录:使用支持访问
Android/data目录的文件管理器(例如 MT 文件管理器),进入路径:/storage/emulated/0/Android/data/org.fcitx.fcitx5.android/files/data/。如果该路径下没有rime文件夹,就新建一个rime文件夹。导入配置文件:将薄荷拼音配置中的所有文件复制或解压到上一步的
rime文件夹内。请注意,复制时要直接放置rime文件夹下的内容,不要在其中再嵌套一层以压缩包命名的文件夹。在小企鹅中添加 Rime 输入法:
打开小企鹅输入法的设置。
找到 "输入法" 选项。
如果 "中州韵" (Rime) 未在输入法列表中,点击右下角的 "+" 按钮添加它。
重载配置:完成文件复制并添加输入法后,你需要重载 Rime 的配置使其生效。在小企鹅输入法的虚拟键盘界面,点击右上角的 "...",然后找到并点击 "重载配置" 选项。
⚙️ 使用与个性化
完成部署后,通常通过点击键盘工具栏上的 "<>" 图标来切换不同的输入方案,例如在薄荷拼音提供的全拼、双拼等方案间选择。
Windows篇
参考视频
https://www.bilibili.com/video/BV1FioQY8EXD
主体:小狼毫
https://github.com/rime/weasel
输入方案(词库):雾凇拼音
https://github.com/iDvel/rime-ice
集成语言模型:RIME-LMDG
https://github.com/amzxyz/RIME-LMDG
rime官方文档
https://rime.im/docs/
雾凇官方文档
https://dvel.me/posts/rime-ice/
万象官方文档
https://github.com/amzxyz/RIME-LMDG/wiki
词库的添加
输入方案(词库):雾凇拼音
https://github.com/iDvel/rime-ice
添加与部署
我使用的方法(还有其他添加方法)是直接从对应仓库clone到用户文件夹目录下,然后点击重新部署
输入方案与配色
输入法设定,仅仅勾选雾凇,其他都取消,配色的话个人比较喜欢致青春/So Young
修改配置文件
然后找到用户文件夹目录下的default.yaml,
方案列表的schema只保留rime_ice也就是雾凇
修改候选词个数为9
注释掉方案选单相关的所有热键
切换简繁,切换中英标点 在下面的快捷键key_binder里面有
- { when: always, toggle: ascii_punct, accept: Control+Shift+3 } # 切换中英标点
- { when: always, toggle: ascii_punct, accept: Control+Shift+numbersign } # 切换中英标点
- { when: always, toggle: traditionalization, accept: Control+Shift+4 } # 切换简繁
- { when: always, toggle: traditionalization, accept: Control+Shift+dollar } # 切换简繁语言模型的添加
集成语言模型:RIME-LMDG
https://github.com/amzxyz/RIME-LMDG
文件添加
用户文件夹目录下添加 万象语言模型 wanxiang-lts-zh-hans.gram
新建文件夹rime_ice.custom.yaml
文件说明
Rime 的配置加载顺序是:
default.yaml → (被 patch 的)schema.yaml → custom.yaml添加配置内容
在rime_ice.custom.yaml中写入
# 启用万象语法模型
patch:
engine/filters/+:
- grammar_filter
grammar:
language: wanxiang-lts-zh-hans
collocation_max_length: 8 #命中的最长词组
collocation_min_length: 3 #命中的最短词组,搭配词频健全的词库时候应当最小值设为3避开2字高频词
collocation_penalty: -10 #默认-12 对常见搭配词组施加的惩罚值。较高的负值会降低这些搭配被选中的概率,防止过于频繁地出现某些固定搭配。
non_collocation_penalty: -12 #默认-12 对非搭配词组施加的惩罚值。较高的负值会降低非搭配词组被选中的概率,避免不合逻辑或不常见的词组组合。
weak_collocation_penalty: -24 #默认-24 对弱搭配词组施加的惩罚值。保持默认值通常是为了有效过滤掉不太常见但仍然合理的词组组合。
rear_penalty: -30 #默认-18 对词组中后续词语的位置施加的惩罚值。较高的负值会降低某些词语在句子后部出现的概率,防止句子结构不自然。
translator/contextual_suggestions: false
translator/max_homophones: 5
translator/max_homographs: 5新添加的配置项解释
engine/filters/+表示在当前 schema 的 filter 列表末尾追加一个过滤器,这样grammar_filter才会实际加载。grammar:区块定义了万象语法模型的配置。这样,Rime 会正确识别
.gram文件(只要放在同目录即可)。
⚠️ 注意:
__include:的方式只在复合 patch 文件(比如雾凇项目的*.octagram.yaml模块)中用得上;
直接写在 custom.yaml 顶层时不会被 schema 引用,因此不会加载。你只需要保留
.gram文件放在同一目录即可,不用显式 include。
问题根源分析
万象模型GitHub主页的配置
__include: octagram #启用语法模型
#语法模型
octagram:
__patch:
grammar:
language: wanxiang-lts-zh-hans
collocation_max_length: 8 #命中的最长词组
collocation_min_length: 3 #命中的最短词组,搭配词频健全的词库时候应当最小值设为3避开2字高频词
collocation_penalty: -10 #默认-12 对常见搭配词组施加的惩罚值。较高的负值会降低这些搭配被选中的概率,防止过于频繁地出现某些固定搭配。
non_collocation_penalty: -12 #默认-12 对非搭配词组施加的惩罚值。较高的负值会降低非搭配词组被选中的概率,避免不合逻辑或不常见的词组组合。
weak_collocation_penalty: -24 #默认-24 对弱搭配词组施加的惩罚值。保持默认值通常是为了有效过滤掉不太常见但仍然合理的词组组合。
rear_penalty: -30 #默认-18 对词组中后续词语的位置施加的惩罚值。较高的负值会降低某些词语在句子后部出现的概率,防止句子结构不自然。
translator/contextual_suggestions: false
translator/max_homophones: 5
translator/max_homographs: 5不能直接套用万象模型GitHub主页的配置文件的原因
Rime 的配置加载顺序是:
default.yaml → (被 patch 的)schema.yaml → custom.yaml原 rime_ice.custom.yaml 是 patch 到 rime_ice.schema.yaml 的补丁。
但前提是 schema 本身声明了 grammar 模块(即 translator 支持 grammar)。
而雾凇拼音默认的 rime_ice.schema.yaml 是这样的:
engine:
...
translators:
- punct_translator
- reverse_lookup_translator
- table_translator
- script_translator注意,它没有加载 grammar 模型。
因此,即使在 rime_ice.custom.yaml 中写了:
__include: octagram系统也不会主动创建 grammar 模块,因为语法模块不是自动加载项。
验证模型是否生效
在候选词窗口中,你可以用以下方式判断语法模型已生效:
联想结果比原先更符合语法逻辑(例如搭配关系词优先出现);
在部署日志中看到
loading grammar model: wanxiang-lts-zh-hans;若部署日志报错
no such grammar, 表示.gram文件路径或名称不匹配。
联想结果验证(模型作者说的简单方法)
最新的LTS配合词库可以完整打出“青花瓷”“最炫民族风”两首歌曲,比如尝试打出
苍茫的天涯是我的爱
这就是舅舅应该做的扩展词库的添加
遇到的问题
音调问题
注意:配合雾凇使用的扩展词库拼音不能带音调
有音调的可以使用nodepad++的正则表达替换,只要替换六次就行
汉语拼音里只有 a/e/i/o/u/ü 这 6 个元音字母会带音调,其他字母(如 b, c, d, … n, m 等辅音)不会有声调符号。
查找内容:
[àáǎā]
替换为:
a
[èéěē]
e
[ìíǐī]
i
[òóǒō]
o
[ùúǔū]
u
[ǜǘǚǖü]
v搜狗词库导出
搜狗导出的词库,这种词汇里包含字母的,就导致那一个字母没法用首字母了(群友之前反应无法使用首字母缩写打句子的问题)
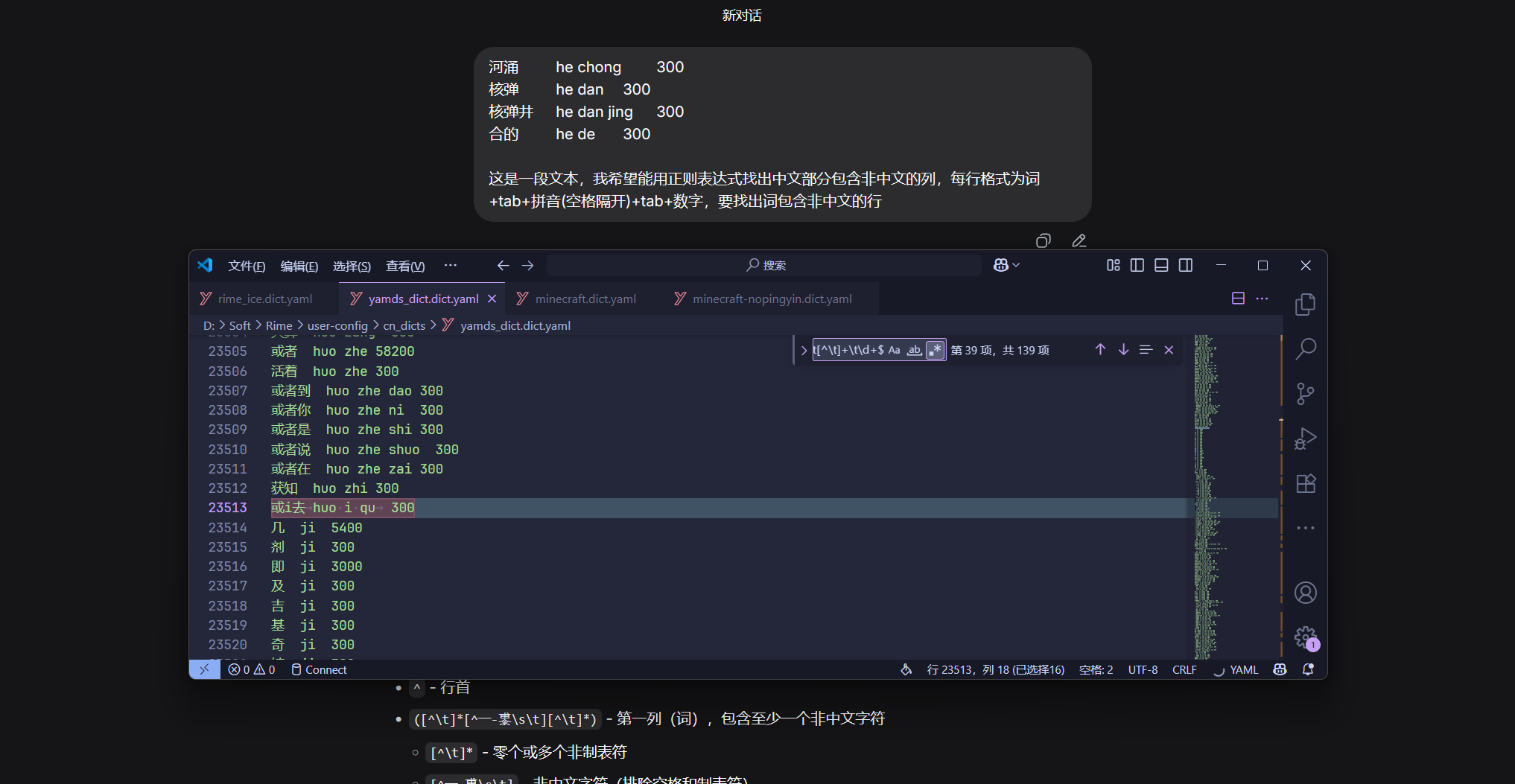
通过创建补丁文件(推荐)
不知道为什么此方法添加失败
为了避免未来更新雾凇词库时发生冲突,决定在rime_ice.custom.yaml文件中添加,也就是通过创建补丁(patch)文件来添加词库
在上文添加万象语言模型的基础上
# 启用万象语法模型
patch:
engine/filters/+:
- grammar_filter
grammar:
language: wanxiang-lts-zh-hans
collocation_max_length: 8 #命中的最长词组
collocation_min_length: 3 #命中的最短词组,搭配词频健全的词库时候应当最小值设为3避开2字高频词
collocation_penalty: -10 #默认-12 对常见搭配词组施加的惩罚值。较高的负值会降低这些搭配被选中的概率,防止过于频繁地出现某些固定搭配。
non_collocation_penalty: -12 #默认-12 对非搭配词组施加的惩罚值。较高的负值会降低非搭配词组被选中的概率,避免不合逻辑或不常见的词组组合。
weak_collocation_penalty: -24 #默认-24 对弱搭配词组施加的惩罚值。保持默认值通常是为了有效过滤掉不太常见但仍然合理的词组组合。
rear_penalty: -30 #默认-18 对词组中后续词语的位置施加的惩罚值。较高的负值会降低某些词语在句子后部出现的概率,防止句子结构不自然。
translator/contextual_suggestions: false
translator/max_homophones: 5
translator/max_homographs: 5
# 增加扩展词库引用
# translator/dictionary: rime_ice
rime_ice/import_tables/+:
- minecraft修改完之后记得 重新部署
说明
"rime_ice/import_tables/+:"
表示在rime_ice.dict.yaml的import_tables列表后追加新的表。my_extend是你的.dict.yaml文件名(不带后缀)。不需要修改雾凇原文件;
未来更新雾凇时,只要
rime_ice.custom.yaml没被删除,你的扩展词库仍然会被自动加载。
直接整合至雾凇主词库
⚠️这是一种较为直接的方法,但请注意,如果未来雾凇词库更新,修改过的文件可能会被覆盖,需要重新操作。
雾凇拼音的主词库一般是:
rime_ice.dict.yaml
可以打开它(在同一个目录下),在 import_tables: 下方添加你的扩展词库名称。例如:
# rime_ice.dict.yaml
---
name: rime_ice
version: "latest"
import_tables:
- rime_ice.base
- rime_ice.extended
- my_extend # ← 加上你的扩展词库名(不含 .dict.yaml)
...任务栏通知区图标更换
群友提供的方法
Android篇
目前个人使用的方案是小企鹅+薄荷
参考视频
https://www.bilibili.com/video/BV1Mr42137Ns
小企鹅输入法项目仓库地址
https://github.com/fcitx5-android/fcitx5-android
小企鹅输入法apk下载
org.fcitx.fcitx5.android-0.1.1-0-g3f41b65d-arm64-v8a-release.apk
小企鹅输入法的rime插件apk下载
org.fcitx.fcitx5.android.plugin.rime-0.1.1-0-g3f41b65d-arm64-v8a-release.apk
薄荷拼音项目仓库地址
https://github.com/Mintimate/oh-my-rime
薄荷拼音官网
https://www.mintimate.cc/
使用体验
优点,很干净
缺点,很干净
感觉常用但缺少的功能
各种输入法长按空格语音转文字
搜狗输入法向上拖动退格键可以删除整行
emoji表情
目前在手机上主要还是使用搜狗,某些更需要隐私的场景可能会使用rime
软件安装
先装小企鹅本体,然后再安装小企鹅的rime插件,
打开小企鹅输入法,点击插件,重新加载插件
点开附加组件,验证插件是否安装成功,显示中州韵就是rime插件安装成功
词库添加
这里选择的手动覆盖安装配置文件
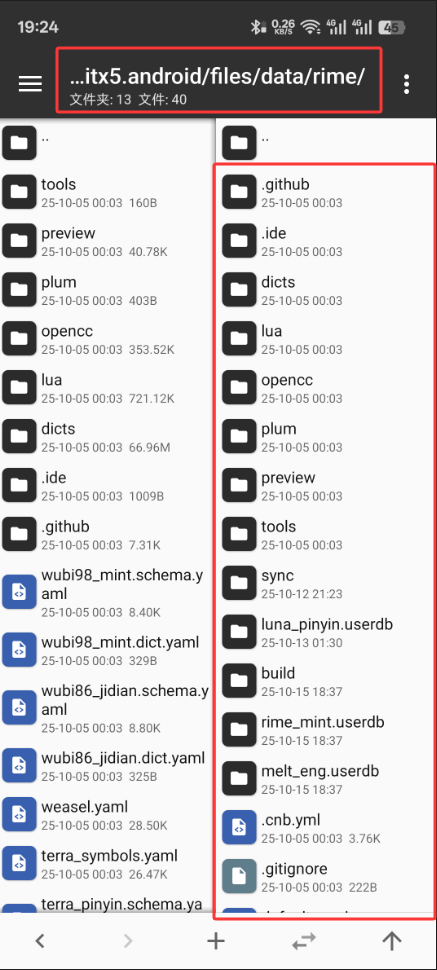
将clone下来的项目压缩包的内容解压到下面路径:
/storage/emulated/0/Android/data/org.fcitx.fcitx5.android/files/data/rime/注意需要正确安装完成rime插件且添加和激活成功才会有此rime目录,没有的话找个可以文本输入的地方弹出输入法点开一下配置,再回来弄

打开小企鹅输入法,点击输入法,点击右下角加号添加中州韵,原来的拼音可以左划删掉

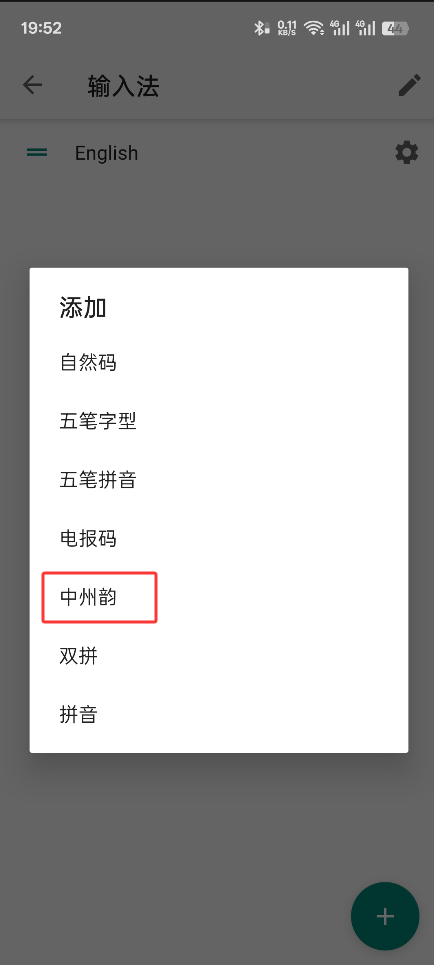
点左上角的右箭头变为左箭头就是展开工具栏,再点三个点图标,默认是 繁体版明月拼音(重载配置暂时用不到)

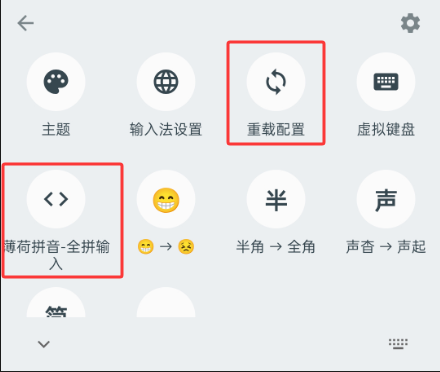
选择两个尖括号的图标,选好薄荷拼音,点重新部署,到此就可以使用了

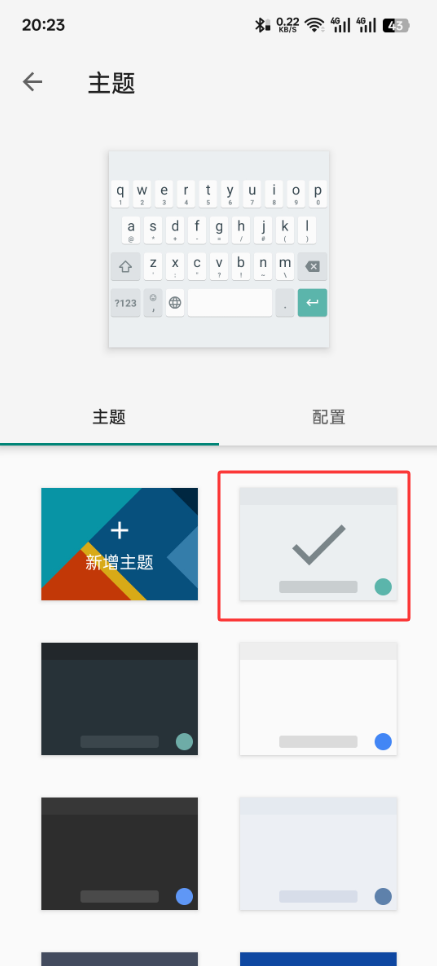
主题
最好改一下,不然没按键边框,整体一片很是不舒服